作为应用广泛的一种统计模型(尤其是在自然语言处理(NLP) 中),隐马尔科夫模型是非常值得一说的,本文就隐马尔科夫模型的原理和应用介绍进行说明。由于隐马尔科夫模型有着很多不同的具体算法实现,本文暂时跳过这部分内容,算法部分会另外写成一篇博文。
马尔科夫链
在语言模型及其实现中,我曾经简单地提到过马尔科夫链,这里将会全面详细的说明。
其实马尔科夫链是一种离散的随即过程,可以将其看成是一种有限自动机,但是其状态之间的转移并不是依赖于外界的输入,而是依赖于每个状态之间的转移概率。
如下图所示:
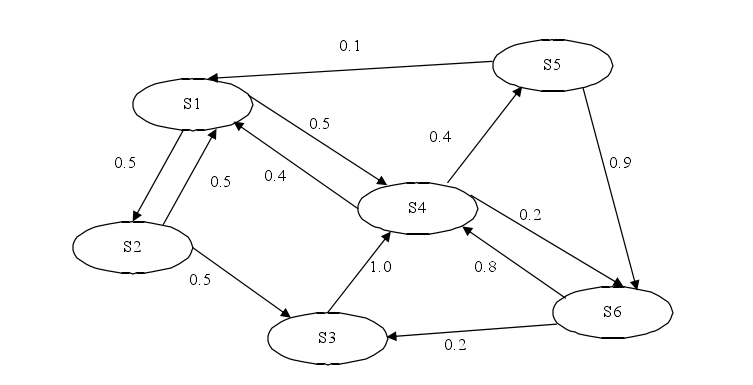
上图中每条边上的权重表示状态转移的概率,对于\(S_1\)来说,用数学语言表达就是:\(P(S_2\vert S_1)=0.5,P(S_4\vert S_1)=0.5\)
现在用更加严谨的数学表达来说明:
假设当前系统中一共有\(N\)个状态,而在每个时刻只可能处于一个状态,所有可能的状态集合用\(S=\{S_1,S_2,\cdots,S_N\}\)表示,用\(q_1,q_2,\cdots,q_n\)表示在时刻\(t=1,2,\cdots,n\)时的状态。
马尔科夫链有两个假设条件,分别是:
-
有限视野:当前时刻的状态只与上一个时刻的状态有关。 用公式表示就是:\(P(q_t\vert q_{t-1}=S_i,q_{t-2}=S_k\cdots)=P(q_t\vert q_{t-1}=S_i)\)
-
时间独立性:状态转移概率与时间无关。 用公式表示就是:\(P(q_t=S_j\vert q_{t-1}=S\_i)=P(q_k=S_j\vert q_{k-1}=s_i)\)
隐马尔科夫模型
而隐马尔科夫模型则是马尔科夫过程的一种扩展,或者说是一种双重的随机过程。隐马尔科夫模型是指,在马尔科夫链中的那些状态\(S=\{S_1,S_2,\cdots,S_N\}\)其实是不可见的,而可见的只是输出的状态\(W=\{W_1,W_2,\cdots,W_T\}\),而从不可见状态到可见状态的转移也存在着一个概率,那些不可见的状态就被称为是隐藏状态,隐马尔科夫模型中的"隐"就是这么来的。
还是先用图来说明吧:
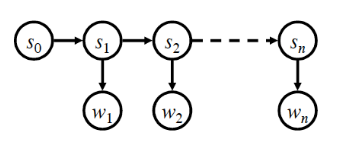
上图中的\(w_1,w_2,\cdots,w_n\)就是被观察到的状态(可见状态),\(s_0,s_1,s_2,\cdots,s_n\)就是隐藏状态(不可见状态).
相对于之前的马尔科夫链,隐马尔科夫模型有以下的不同之处:
- 观察状态与隐藏状态之间存在概率关系
- 多一个假设条件,输出独立性:可见状态仅与当前状态有关,用公式说明就是:\(P(W_1,W_2,\cdots,W_n\vert S_1.S_2,\cdots,S_n)=\prod\limits_{n}P(W_i\vert S_i)\)
隐马尔科夫模型可以用一个五元组来表示:\(\lambda=(S,W,A,B,\pi)\),其中:
- \(S\)表示隐藏状态集合,\(S=(S_1,S_2,\cdots,S_N)\)
- \(W\)表示观察状态集合,\(W=(W_1,W_2,\cdots,W_N)\)
- 状态序列\(Q=q_1,q_2,\cdots,q_T\)(隐藏),观察序列\(O=o_1,o_2,\cdots,o_T\)(可见)
- \(A\)是状态转移概率分布\(A=[a_{i,j}],a_{i,j}=P(q_t=s_j\vert q_{t-1}=s_i)\)
- \(B\)是观察值生成的概率分布\(B=[b_j(v_k)],b_j(v_k)=P(o_t=v_k\vert q_t=s_i)\)
- \(\pi\)是初始的状态概率分布,\(\pi=[\pi_i],\pi_i=P(q_1=s_i)\)
应用
到目前为止所说的隐马尔科夫模型都是太抽象了,仅仅知道它是什么还不能帮助我们完全理解它作用,下面就通过两个隐马尔科夫模型的应用,来说明这个模型的强大之处。
词性标注
在自然语言处理中,词性标注是一个非常基本的任务,简单来说,每一个词,不管是中文还是英语,它在句子中一定会有一个词性标记1,比如名词、形容词等等。确定一个句子中每一个词的词性,是一个最基本的任务,它为后续的其他处理提供了基础信息。
在词性标注的任务中,我们可以将一个句子看成是可见状态序列,每一个词都是一个可见的状态(\(o_i\)),而每一个词都对应着一个词性,这个词性就是隐藏状态(\(q_i\)),而整个文本中的所有词汇表就是观察状态的集合(\(W\)),预定义的词性标记集就是隐藏状态集合(\(S\))。而我们的目标是,在给定一个观察序列\(O\)(句子,或者可以看成是词组的序列)的情况下,寻找其对应的隐藏状态序列\(Q\)(每一个词对应的词性标记)。
拼音输入法
隐马尔科夫模型另外一个比较重要的应用就是拼音输入法,目前主流的拼音输入法或多或少地运用到了隐马尔科夫模型。
在输入法的应用中,我们可以将用户输入的拼音序列看成是可见的状态序列,而拼音所对应的汉语词语就是不可见的隐藏状态,我们的目标是就是在给定拼音序列的情况下,寻找概率最大的隐藏状态序列。如下图所示:
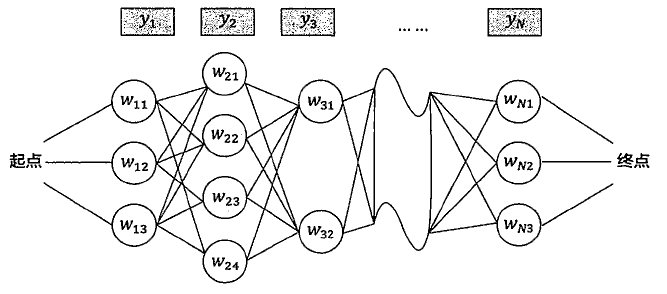
其中,\(y_1,y_2,\cdots,y_N\)表示用户输入的拼音串(可见状态),\(w_{11},w_{12},w_{13}\)表示第一个拼音\(y_1\)的候选汉字,其他的依次类推。
总结
在本篇文章中,只是着重介绍了马尔科夫过程和隐马尔科夫模型及其应用,具体的算法实现全部略过了,这是因为其实现算法中也包含了很多的内容,因此我打算将算法部分单独写成一篇博文,本篇文章中就没有涉及算法部分的内容了。
这里可以做一下简单的说明,隐马尔科夫模型的实现过程,主要有两大步骤:
-
模型参数的学习,也即要学习获得隐马尔科夫模型5个要素中的转移概率矩阵\(A\)和\(B\).这个过程主要有两种方法,分别是基于监督方法的极大似然估计和基于非监督方法的EM算法。
-
模型解码,也即在给定转移矩阵和可见转台序列的情况下,如何寻找到最有的隐藏状态序列,这个过程可以利用基于动态规划思想的Viterbi算法来解决。
参考资料
- Wiki:马尔科夫链
- 隐马尔科夫模型(HMM)及其扩展
- 《数学之美》-吴军
-
同一个词在不同的句子中,可能具有不同的词性标记。 ↩