首先需要明确的是,EM算法其实是一种算法策略,而不是一种具体的算法,从这个角度可以类比成动态规划算法,动态规划也只是一种算法设计的策略,对于具体的问题,EM和动态规划都有不同的形式,但是基本思想是不变的。
其次,需要知道的是,什么样的问题是适合用EM算法来求解? EM算法是针对包含有隐变量的问题进行求解的方法,对于不包含隐变量的问题,我们根本不需要用EM这把牛刀。
举例来说,如果现在已知某校的男生的身高是符合正态分布的,并且已经在全校范围内独立抽查了100名男生的身高,现在需要你估计该正态分布的参数(即\(\mu\)和\(\sigma\))。对于这样的问题来说,我们只需要采用极大似然估计的方法,配合上梯度下降算法,很简单就能解决这个问题。
但是,如果已知学校中男女生的身高都是符合正态分布的,而参数不同,并且在全校范围内独立抽查了200名学生的身高,但是却没有记录其性别,只知道身高的数据。那么,在这种情况,请你分别求解男女生身高正太分布的参数。对于这个问题,单纯使用极大似然估计就不能解决问题了,此时就需要EM这把牛刀了。
这同样也可以用动态规划来类比:对于能够使用贪心策略解决的问题就不需要用动态规划这把牛刀了。
极大似然估计
现在我们首先来看一下,什么才是极大似然,这是理解EM算法的第一步。
回到上面的第一个例子,我们将其转化为数学化的描述:
令\(\theta=[\mu,\sigma]\)表示正态分布的参数,在全校范围内我们独立同分布的采样了100名男生的身高,由于我们已知男生的身高是符合参数为\(\theta\)的正太分布的,所以每一个被采样的男生的身高都符合概率密度函数:\(p(x\vert \theta)\),其中\(x\)表示身高。而采样的结果我们用\(X=\{x_1,x_2,\cdots,x_N\}\)来表示,其中\(N\)表示采样的总人数。
由于这100个男生是独立随机地从\(f(x\vert \theta)\)中采样的,因此采样到1号男生的概率应该是\(p(x_1\vert \theta)\),同理2号男生的概率是\(p(x_2\vert \theta)\)...那么对于这100个男生的来说,他们同时被采样到的概率就是:
上述这个公式表明了在给定\(\theta\)这个参数的情况,\(X\)这一组数据被采样到的概率是多少。那么在什么情况下,这一组\(X\)会被采样到呢?当然是这组\(X\)数据出现的概率最大的时候!而上述这个\(L(\theta)\)就是用来衡量\(X\)出现的概率的,由于\(X\)是已知的,所以\(L(\theta)\)是关于\(\theta\)的函数,因此,我们只需要使得这个函数达到最大值,即\(X\)这一组数据被抽取到的概率最大时对应的\(\theta\)就是我们需要的\(\theta\).
所以,最终我们需要求的\(\theta\)就是:
连乘是比较麻烦的,我们可以将其改造成连加:
其中\(L(\theta)\)称为似然函数,而\(H(\theta)\)称为对数似然函数.
总结一下,其实极大似然指的是一种又果到因的参数估计方法,通常我们都是由因到果的,而极大似然则是在知道结果的基础上,由结果来倒推原因。具体原理就是在知道结果的情况下,列出可能的所有原因,在这些可选的原因中选取一个,使得已知结果出现的可能性最大。极大似然的核心思想就是:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
极大似然的一般步骤如下所示:
- 写出似然函数
- 改写成对数似然函数,整理
- 求导,令导数为0,得到似然方程
- 解似然方程,得到参数\(\theta\)
Jensen不等式
在正式说明EM算法之前,我们需要了解一个很有用得数学工具,称为Jensen不等式,这在优化理论中是一个比较重要的不等式。
设\(f\)是定义域为实数的函数,如果对于所有的实数\(x\),\(f(x)\)的二阶导数大于等于0,那么\(f\)是凸函数。当\(x\)是向量时,如果其hessian矩阵\(H\)是半正定的,那么\(f\)是凸函数。如果只大于0,不等于0,那么称\(f\)是严格凸函数。
Jensen不等式描述如下:
如果\(f\)是凸函数,\(X\)是随机变量,则\(E[f(x)] \ge f(E[X])\),当且仅当\(X\)为常量时,等号成立。如下图所示:
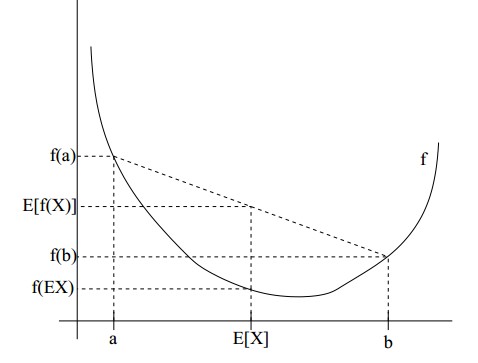
如果\(f\)是一个凹函数,则不等号取反。
EM算法
现在我们回到上述的第二个例子中,也就是我们同时男女生的身高数据,同时又不知道具体哪个数据是男生的,哪个是女生的,在这种情况需要你估计男女生正态分布的不同参数。
由于我们此时不知道采样得到的数据到底来自女生还是男生,所以我们无法直接使用上述极大似然估计的方法来求解其参数,此时我们称这样的数据是包含隐变量的,这个隐变量就是用来指明具体的每一个数据来自哪一个分布(男生的还是女生的).由于这个隐变量是未知的,所以这就造成了我们的困难。
首先,我们可以将采样得到的数据表示成一个二元组:\((x_i,z_i)\),其中\(x_i\)表示第\(i\)个人的身高,\(z_i\)表示这个被采样的人是男(用1表示)的还是女(用0表示)的.
根据联合分布的概率和,我们有\(p(x_i;\theta) = \sum\limits_{z_i}p(x_i,z_i;\theta)\).
让我们将这个改写后的数据返回到之前的极大似然估计中,我们可以得到:
还是和极大似然估计中一样,我们需要使得\(H(\theta)\)达到最大值,最常规的做法就是对\(H(\theta)\)进行求导,令其导数为0.但是这和之前不含隐变量的函数不同,这个函数比较复杂,包含了"和的对数 ",直接求导是非常困难的,其实这就是隐变量带来的困难之处了。
为了解决这个求导的问题,我们可以对等式\(\ref{original}\)做一些改变,令\(Q_i\)表示变量\(z_i\)的某种分布,且\(Q_i\)满足\(\sum\limits_{z_i}Q_i(z_i)=1,Q_i(z_i) \ge 0\),利用这个\(Q_i\),我们可以将等式\(\ref{original}\)改变为:
此时,\(\sum_{z_i}Q_i(z_i) \cdot \frac{p(x_i,z_i;\theta)}{Q_i(z_i)}\)其实就是\(\frac{p(x_i,z_i;\theta)}{Q_i(z_i)}\)的期望,同时\(\ln\)又是一个凹函数,因此我们能够直接套用Jensen 不等式:
进行了上述变换之后,我们就避免了计算"和的对数 ",变成了计算"对数的和 ",这可简单得多了。但是,这里你也许会问,我们明明要求的是\(H(\theta)\)的最大值,可是这里怎么会是一个"大于等于"呢?这只是一个下界!的确,目前我们所得到的确实是一个下界,我们能够通过不断提高这个下界,逐渐逼近\(H(\theta)\),我们稍后会做说明。
首先我们来看一下,等号成立的条件,在Jensen 不等式中,等号成立的条件是随机变量\(X\)为一个常量,因此令\(\frac{p(x_i,z_i;\theta)}{Q_i(z_i)}=c\),又因为\(\sum\limits_{z_i}Q_i(z_i)=1\),因此,我们可以得到\(p(x_i;\theta)=c\).(多个等式分子分母相加不变),将其代回,我们可以得到:
如此一来,我们就能在给定\(x_i,\theta\)的情况下,计算出\(Q_i(z_i)\)了,而知道了\(Q_i(z_i)\)之后,我们又能重新估计参数\(\theta\),这似乎有点类似鸡生蛋,蛋生鸡的问题,我们从中打破了其中的一步,可以将\(\theta\)随机赋一个初始值,然后估计\(Q_i(z_i)\);再利用新的\(Q_i(z_i)\)估计\(\theta\),如此反复迭代下去,直至收敛。其实这就是EM算法的基本思想了。在我们重新估计新的\(\theta\)的时候,其实就是在不断提高\(H(\theta)\)的下界,以达到最大值。
EM的具体过程如下:
-
E步: 对于每一个\(i\),计算\(Q_i(z_i) = p(z_i\vert x_i;\theta)\)
-
M步: 计算
参考资料
- 从最大似然到EM算法浅解
- (EM算法)The EM Algorithm
- EM
- Dynamic Programming
- Maximum Likelihood
- Gradient Descent
- Greedy Algorithm
- Jensen Inequality