什么是决策树
其实网络上有着很多说明决策树的文章,比如参考资料中的1和2,主要是因为这个机器学习的方法实在太经典了,有着很多不同的算法实现,包括最早的由Quinlan在1986年提出的ID3算法、1993年同样是Quinlan提出的C4.5算法以及由Braiman等人在1984年提出的CART算法。
尽管这个模型如此的"尽人皆知",但是此处还是要说明一下,到底什么才是决策树。
决策树模型其实是一种描述决策过程的树形结构,既可以用来分类也可以进行回归分析。一个决策树就是一个树结构,它是由节点和有向边组成的。其中的节点又分为两类:叶节点和非叶节点。叶节点表示一个候选的类别,非叶节点表示一次属性的判断,该节点的每一个后继分支都对应于该属性的一个可能值。
预测的过程就是一个从根节点开始的寻找路径的过程(也可以说是一个决策的序列),从根节点开始,根据样本中的每一个属性值,在非叶结点中选择一个分支往下走,直至到达叶节点,此时叶节点所代表的类别就是该样本预测的类别。如下图所示:
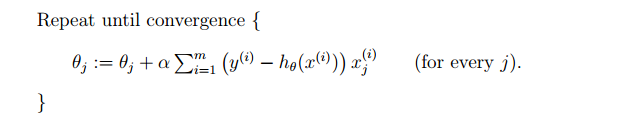
根据决策树的预测过程,其实我们可以将决策树看成是一个if-else的规则集合,每一条从根节点到叶节点的路径都对应着一条if-else规则,但是需要注意的是,此处有一个重要的性质:
互斥完备性: 每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则覆盖
决策树的优点和缺点
首先我们来看一下决策树模型具有哪些优点:
- 学习和预测过程简单明了,对于学习到的模型方便解释。
- 数据预处理少,不需要进行正规化等数据预处理操作。
- 能够处理任意的数据类型(实数值和离散值)。
- 没有过强的假设条件,比如在朴素贝叶斯模型中有属性之间是条件独立的假设,而在决策树中没有预设的假设,该模型仅仅依靠观测到的数据。
当然,任何一个模型都不会只有优点而没有缺点的,决策树的缺点有如下几点:
- 寻找一个最优的决策树其实是一个NP难题,目前所用的决策树生成算法都是一种基于启发式的贪心算法,每一个节点根据某种预设的判定规则进行节点的分裂,最终得到的决策树不能保证是全局最优的,只能说是局部最优。
- 容易发生过拟合的情况,尤其当树生长层次特别深的时候,往往都会发生过拟合现象。(这个问题可以通过进行剪枝技术来解决。)
决策树的学习过程
一棵决策树的生成过程主要分为以下3个部分:
-
特征选择: 特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同的标准,常用的有:信息增益、信息增益比和Gini指数。
-
决策树生成: 根据选择的节点分裂标准,从上至下递归地生成子节点1,直到某个节点不满足分裂的标准,则停止决策树停止生长。
-
剪枝: 由于决策树存在着过拟合的风险,所以一般来说需要对生成的决策树进行剪枝操作,缩小树结构的规模,缓解过拟合的现象。其实这个过程并不是必须的,比如在最早的ID3算法中,就没有剪枝的过程,但是在实际分析数据的时候,往往都会出现过拟合的现象,所以通常在生成树结构之后会进行剪枝操作。
参考资料
- July大神的<从决策树学习谈到贝叶斯分类算法、EM、HMM>
- Decision Tree:Analysis
- <统计机器学习>——李航
- <机器学习>Tom M.Mitchell
-
其实具体代码实现的时候,不一定就是递归的,但是此处对于树结构来说,递归结构是最容易理解的方式。 ↩